neoRL.net
R&D Services for innovative projects on digitalization; technology development; project management and soft funding.
[ neoRL ] [ demonstration ] [ about the author ]
TODO Ta bort denne, og/eller bytt den ut med noko betre. TODO
Real-time learning videos
The following demonstrations are examples of autonomous navigation in the allocentric WaterWorld environment (not the simpler egocentric javascript-version); controlling acceleration in 2 directions, the agent is set to catch green entities while avoiding red. The agent is initiated at the beginning of the video, with no precursors other than what is described in the listed articles.
All is learned –– every aspect of the blue-dot’s control is self-governed. Autonomous navigation is made possible by acquired experience from off-policy learning. Off-policy learning allows for learning by demonstration, something that would further improve performance. Observe the real-time improvement by comparing initial and final proficiency in each video!
Note that the WaterWorld environment involves temporal dynamics due to intertial mechanics, best described as `` driving on ice’’. Results from the WaterWorld environment is directly applilcable to maritime autonomy.
Recurrent desires in neoRL networks
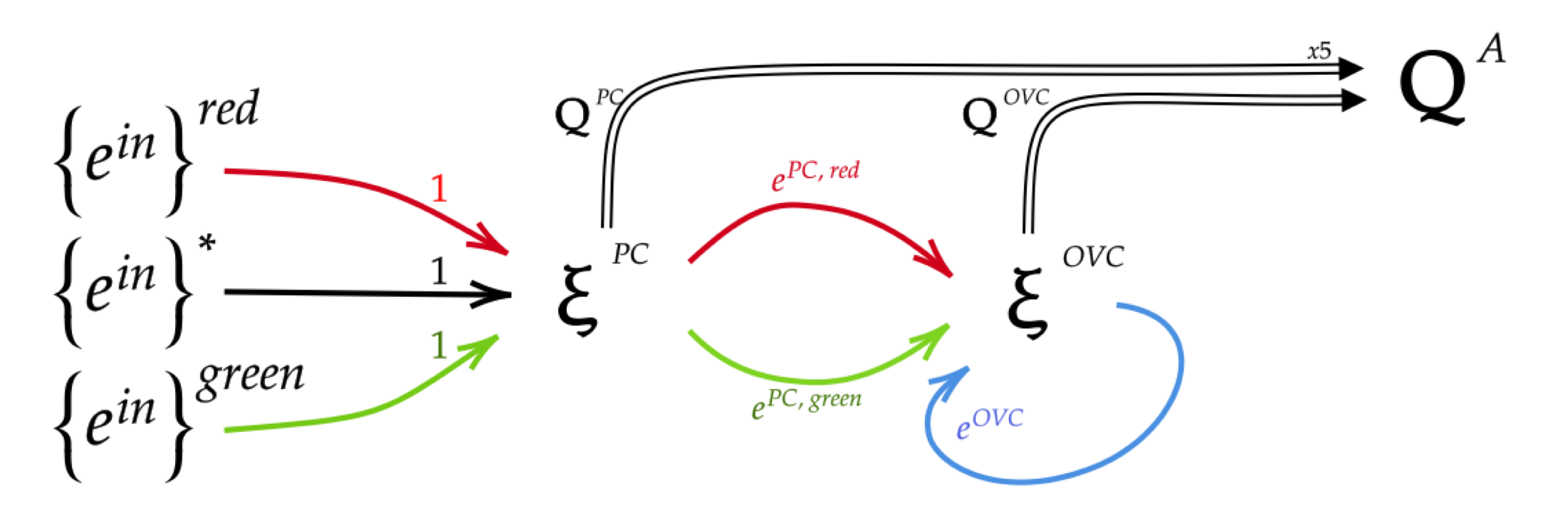
A video of recursive desire-structures – full category II autonomy. The first layer learns Q-values according to the place-cell representation. When actions have a Euclidean significance, state-action values can be interpreted as a desire vector. Desire vectors can establish desires for deeper neoRL nodes. Agent design is illustrated in the figure on the left of this page.
(Objective: Catch green dots, avoid red, until there are no green left –– upon which the board is reset. All behavior is learned – autonomous navigation) —-
Externally supplied desires.
For more Elements-of-Interest (EoI), the navigation challenge becomes difficult; here mastered by a PC + OVC collaborative neoRL agent with 0th order desires – where agent desire is directly governed by the location of EoI in each NRES modality. With all EoI being algorithmically defined, this video demonstrates an agent with category I autonomy.
Autonomous desires for 8EoI
For comparison, navigation by autonomous desires is possible, i.e., a full category II autonomy according to the illustration to my left. 8 elements of interest makes this challenge difficult for a human pilot, requiring constant vigilance for longer periods of time. The neoRL agent is capable of proficient navigation without becoming tired. See Towards neoRL networks; the emergence of purposive graphs